The Human Bottleneck in AI Decision-Making
For years, Reinforcement Learning (RL)—the tech behind AI’s ability to make decisions (like AlphaGo’s moves or MuZero’s planning)—has relied on top human experts. Every improvement, from designing reward systems to tweaking algorithms for tricky scenarios (sparse rewards, hidden environments), took years of trial-and-error. Even in simple games like Atari or maze navigations, human-crafted rules often struggled to balance short-term actions and long-term goals.
Breakthrough: Machines Now Invent Their Own RL Algorithms
In October 2025, Google DeepMind’s Nature-published study introduced DiscoRL, a method where AI teaches itself RL rules through “meta-learning.” Developed by David Silver’s team, DiscoRL doesn’t just optimize existing algorithms—it discovers entirely new ones, marking the shift from “human-tweaked RL” to “AI-created RL.
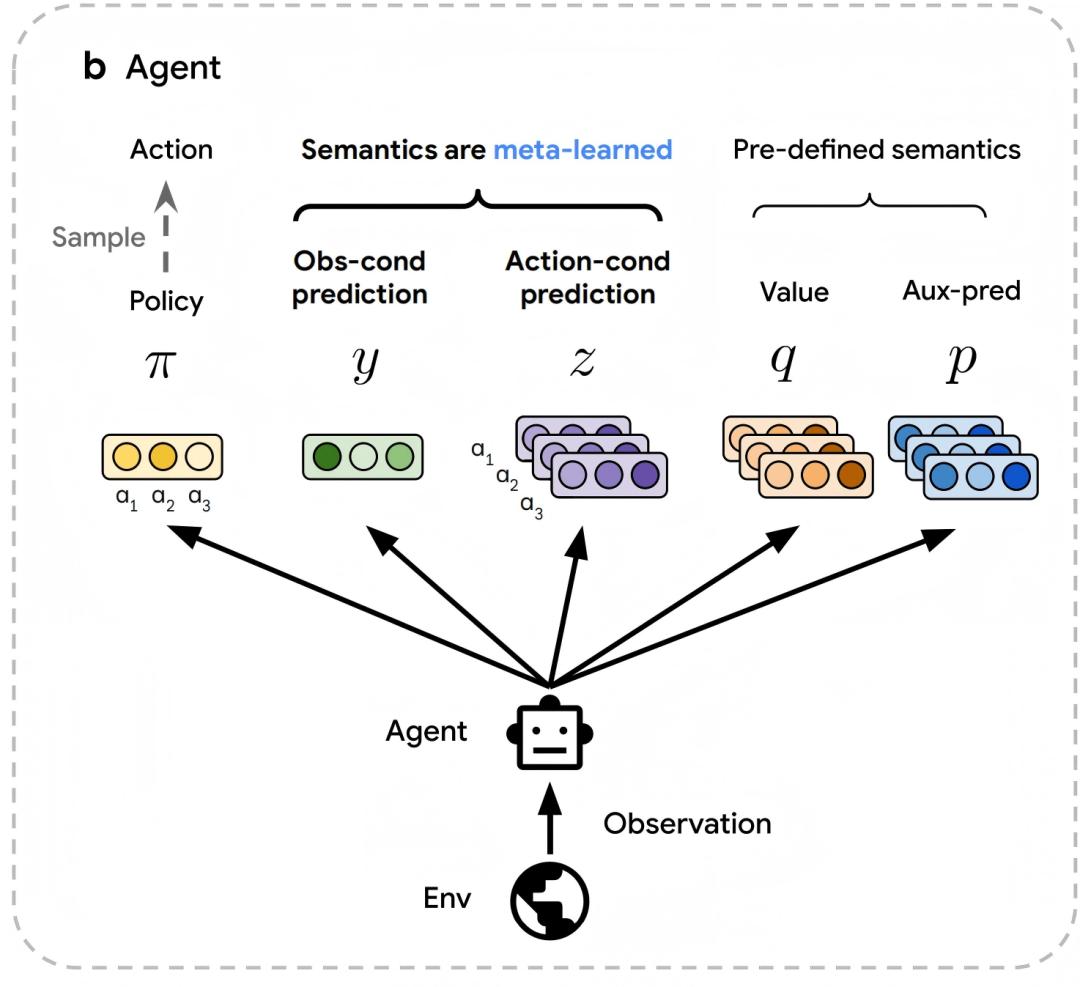
“How It Works: A Self-Evolving AI “Lab”DiscoRL’s magic lies in its two-layer system:
- The Learner (Agent): Instead of using pre-set formulas, it generates flexible predictions (like observing patterns and planning actions) alongside basic tools (like action values) to guide discovery.
- The Designer (Meta-Network): This “AI engineer” analyzes the learner’s experiences (actions, rewards, etc.) and crafts new optimization rules. It’s like a coach that watches gameplay, then invents better training methods—no human input needed.
The two layers work together: the learner improves by matching the designer’s rules, while the designer refines those rules to maximize rewards. Bonus: it’s super efficient, using shortcuts to process tons of data quickly.
Proof It Works: Smashing BenchmarksTested on 103 complex environments (from Atari games to the ultra-hard NetHack maze):
- Atari 57 Games: DiscoRL’s trained rule (Disco57) beat classic algorithms like MuZero, scoring higher with just 600 million steps per game (humans needed months of tweaks!).
- New Environments: It aced unseen games (ProcGen), thrived in survival challenges (Crafter), and ranked 3rd in the NetHack Challenge—all without knowing game specifics.
- Diverse Training Wins: When trained on 103 mixed tasks, DiscoRL’s rules mastered Crafter (human-level) and Sokoban (near-top scores), while rules trained on simple tasks failed in harder games.
Why It Matters: The Future of AI
DiscoRL isn’t just a cool trick—it’s a game-changer for AI development:
- Faster Innovation: No more years of human coding; AI generates optimal rules with just data and computing power.
- Path to Super Intelligence: Shows RL rules can emerge from pure interaction, paving the way for more general AI.
- Real-World Ready: Ideal for robots or self-driving cars that need to adapt instantly to new situations—no human reprogramming needed.
The Big Picture
DiscoRL proves machines can now design their own “learning blueprints,” even uncovering new algorithm tricks humans missed (like predicting future rewards). As AI learns to create its own methodologies, we’re entering an era where it doesn’t just solve problems—it evolves how it solves them. The future? Machines designing smarter machines, with humans stepping back from the formula grind. Welcome to the age of AI-created AI.







